”nodejs twitter twitter-api twitter-streaming-api TwitterJavaScript“ 的搜索结果
spark-streaming-flume_2.11-2.1.0.jar
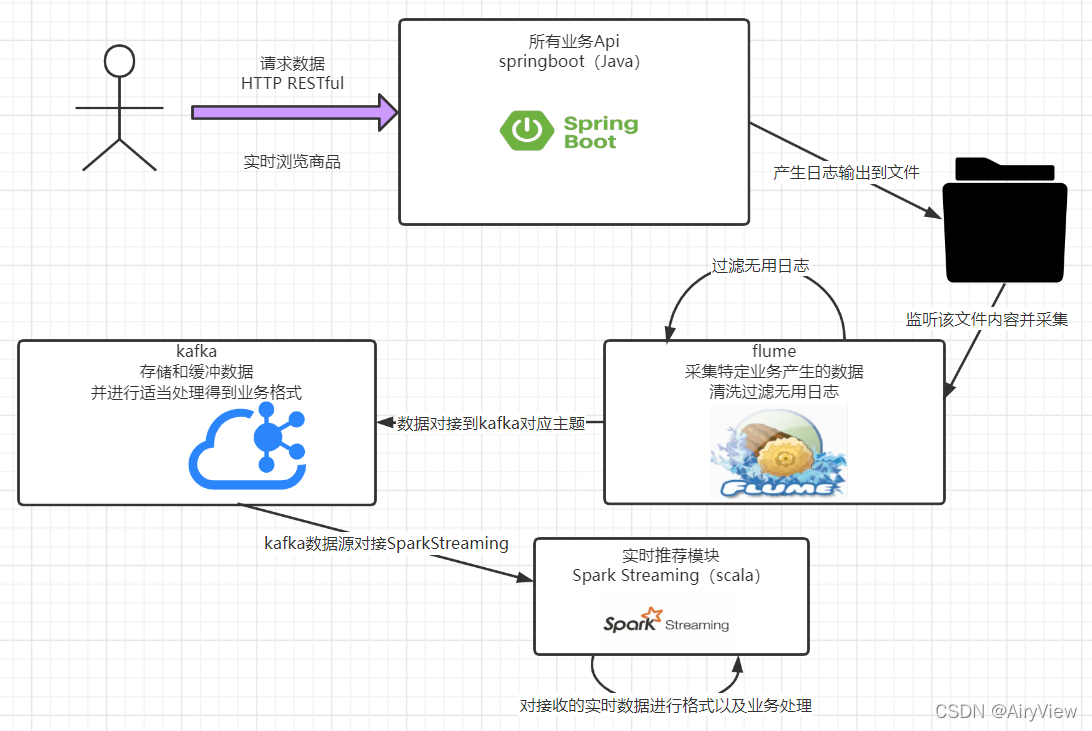
1. 任务列表模块分析 任务列表模块如下图所示,其中新增和修改任务操作,对应到 job_config表里面... flink-streaming-web 模块 -> controller包 -> api 包里面 1.1 新增任务流程 -> addPage.ft...
前言 引用Spark commiter(gatorsmile)的话:“从Spark-2.X版本后,Spark streaming就进入维护模式,Spark streaming是低阶API,给码农用的,各种坑;Structured streaming是给人设计的API,简单易用。由于太忙,...
1、实例演示 1.1 流数据模拟器 1.1.1 流数据说明 在实例演示中模拟实际情况,需要源源不断地接入流数据,为了在演示过程中更接近真实环境将定义流数据模拟器。该模拟器主要功能:通过Socket方式监听指定的端口...
要点如下:按照惯例,先看一下最初的数据密集型应用架构,指明我们所感兴趣的SparkStreaming模块的所处位置.下图着重指明了整体架构中的SparkStreaming模块,SparkSQL和SparkMLlib:数据流可以来自
1、Spark Streaming简介 1.1 概述 Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis ...

nats-streaming-cluster Nats-Streaming Cluster By Docker Compose Nats-Streaming Cluster By Kubernetes github 项目地址,有问题欢迎讨论 Support Docker-Compose Deploy nats + nats-streaming 集群方案 1 ...
docker-nginx-rtmp - NGINX-based Media Streaming Server https://github.com/alfg/docker-nginx-rtmp A Dockerfile installing NGINX, nginx-rtmp-module and FFmpeg from source with default settings for HLS ...

Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后...
pyspark提交kafka任务缺少spark-streaming-kafka-0-8-assembly.jar报错解决方案 1、开启kafka生产端 [root@hadoop102 ~]# kafka-console-producer --broker-list hadoop102:9092 --topic test1 2、pyspark接收...
spark streaming kafka
第1关QueueStream import java.text.SimpleDateFormat import java.util.Date import org.apache.spark.{...import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.collection.mutable ob.
Flink学习-DataStream-HDFSConnector(StreamingFileSink) 摘要 本文主要介绍Flink1.9中的DataStream之HDFSConnector(StreamingFileSink),大部分内容翻译、整理自官网。以后有实际demo会更新。 可参考Streaming...
来源:http://blog.csdn.net/eric_sunah/article/details/54096057?utm_source=tuicool&utm_medium=referral 说明 Spark Streaming的原理说明的文章很多,这里不做介绍。...spark streaming:ht

1、Spark Streaming简介 1.1 概述 Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后...
spice-streaming-agent从官方的定义介绍,是一个运行于guest os中的守护进行,捕捉guest os的视频输出,编码成视频流后通过spice-protocol协议转发给host主机。 1. 安装 spice-streaming-agent源码下载:...

title subtitle tags grammar_cjkRuby catalog layout header-img preview-img categories date Lab Streaming Layer LSL数据流 LSL 数据流 true tr...
kafka+Sparkstreaming环境搭建与配置说明以及相关的测试代码的编写
本关任务:编写一个清洗QueueStream数据的SparkStreaming程序。 import java.text.SimpleDateFormat import java.util.Date import org.apache.spark.{HashPartitioner, SparkConf} import org.apache.spark.rdd...
Spark-Streaming Job的生成和执行可以通过如下图表示: Spark-Streaming Job的生产和和执行由以下3个部分相互作用生成: Driver程序:用户通过编写Driver程序描述了DStream的依赖关系,Driver程序根据DStream描述...
大数据系列-SPARK-STREAMING流数据queue package com.test import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.{Seconds, StreamingContext} import scala....
大数据系列-SPARK-STREAMING流数据state package com.test import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{...
推荐文章
- Pytorch Dataloader 模块源码分析(二):Sampler / Fetcher 组件及 Dataloader 核心代码-程序员宅基地
- Asp类型判断及数组打印-程序员宅基地
- Adroid Studio 2022.3.1 版本配置greendao提示无法找到_plugin with id 'org.greenrobot.greendao' not found-程序员宅基地
- esxi查看许可过期_解决Vsphere Client 60天过期问题-程序员宅基地
- CMake_cmake_module_path-程序员宅基地
- 生产者消费者模型-程序员宅基地
- Adaptive AUTOSAR 解决方案 INTEWORK-EAS-AP_autosar的eas-程序员宅基地
- 穿山甲SDK错误码40025_穿山甲sdk错误码4025-程序员宅基地
- css firefox下的兼容问题_css 只用于firefox-程序员宅基地
- 【Python】对大数质因数分解的算法问题_python分解多个质因数代码-程序员宅基地